
If you read my original content cruft cleanup post, you know I’m a big believer in content pruning. I did the great content pruning cleanup of 2017 by hand. Google Analytics in one tab, WordPress in another, Notepad++ and Excel doing the sorting. It worked. It also took forever.
This year I did another round of content pruning on the same blog, but this time I didn’t do it alone. I had an agent do most of the clicking while I made the calls.
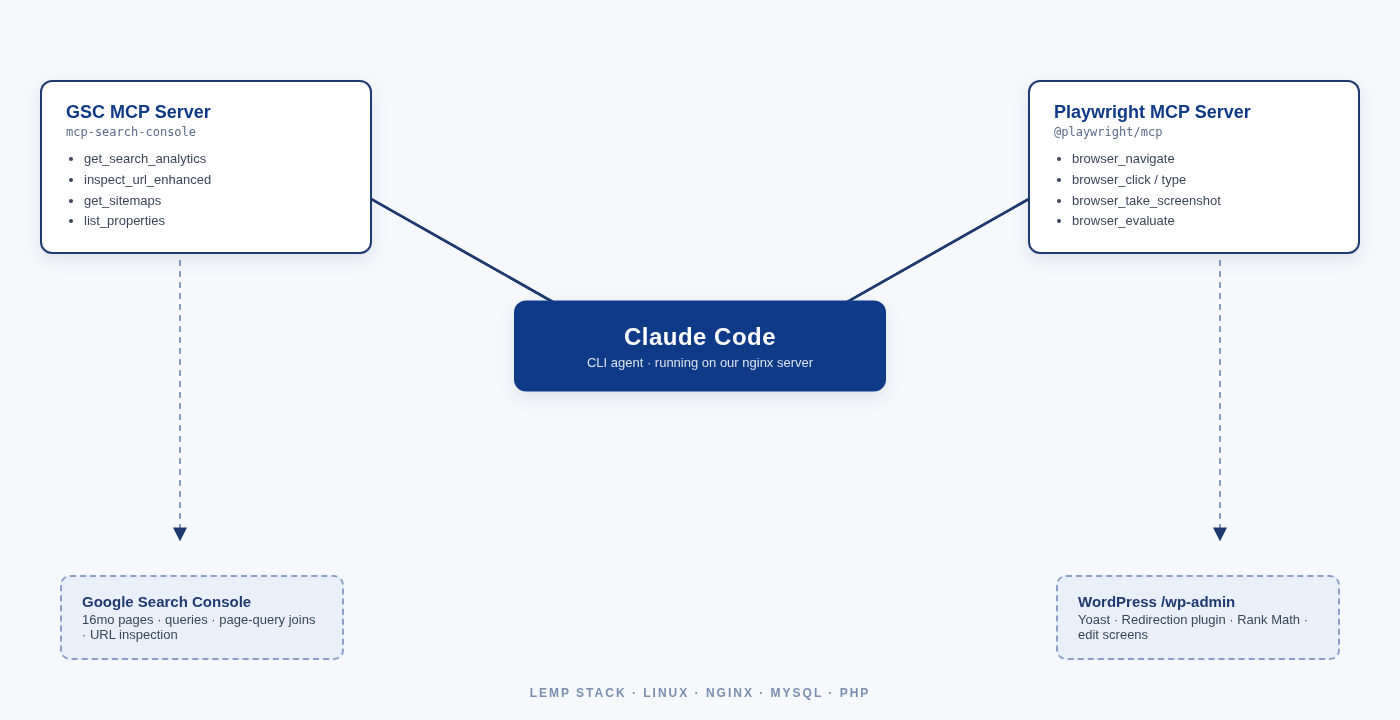
The short version: Claude Code running on the command line of our own nginx server, two MCP servers (one for Google Search Console, one for Playwright), and the ever-reliable wp-cli doing most of the actual WordPress edits. Honestly, it’s the most fun I’ve had doing an SEO audit in years :) The base methodology is still the same one we use on every technical SEO engagement we deliver, just dramatically accelerated by having an agent do the per-page judgment calls in parallel.
A quick note for anyone who hasn’t touched MCP yet. MCP stands for Model Context Protocol. Think of an MCP server like a WordPress plugin, but for an AI agent. It’s a small piece of software that plugs a specific capability into the agent. A Google Search Console MCP server gives the agent access to your GSC data. A Playwright MCP server gives it a real browser. You don’t write any integration code. You point the agent at the MCP servers and they show up as tools it can use.
IN THIS POST
- The Stack
- Finding Crufty Pages, The 2026 Agentic SEO Edition
- Sorting Into Categories
- The Human Element: Every Verdict Must Be Human-Reviewed
- The Part I Wasn’t Expecting: This Got Emotional
- Chaining Multiple Claude Code Windows
- Executing the Verdicts (wp-cli Does the Heavy Lifting, Playwright Verifies)
- The Numbers (So Far)
- What’s Next: Where I’m Taking This
- What This Doesn’t Change
The Stack
We run a pretty standard LEMP stack here (Linux, nginx, MySQL, PHP) on our own box, and I installed Claude Code right on that server. No cloud service in the middle, no SaaS dashboard. Just the CLI talking to two MCP servers on the same machine:
- Claude Code, Anthropic’s command-line agent, installed on our nginx server. We have a dev server running on the same machine as our production server.
- wp-cli (installed on the same nginx box). Does most of the actual WordPress edits. Bulk postmeta updates, Redirection plugin imports, media library management. Faster and more atomic than clicking through /wp-admin.
- Google Search Console MCP server (the
mcp-search-consolepackage). Gives the agent live access to our GSC data, 16 months of pages, queries, page-query joins, URL inspection, sitemap state. - Playwright MCP server (Microsoft’s
@playwright/mcp). Gives the agent a real Chrome browser it can drive. It can log into/wp-admin, click through Yoast, flip noindex toggles, paste CSVs into the Redirection plugin.
wp-cli handles the bulk WordPress edits. It writes to the database atomically, it’s scriptable, and for postmeta updates and Redirection plugin imports it’s faster and safer than a browser. Playwright handles the browser-side verification, loading changed URLs, reading meta tags, grabbing screenshots for the audit log. Two tools, different jobs, both sitting behind the same Claude Code session.
One thing I want to call out: I also looked at the Screaming Frog MCP projects floating around out there. Screaming Frog has been in my SEO toolkit forever and I was tempted. In the end I didn’t bother for this round. Between GSC (what’s indexed and ranking) and the WordPress REST API (what’s actually on the site), I had enough to work with. I’ll probably revisit this for the next cleanup when I care more about on-page signals and link equity across the archive.
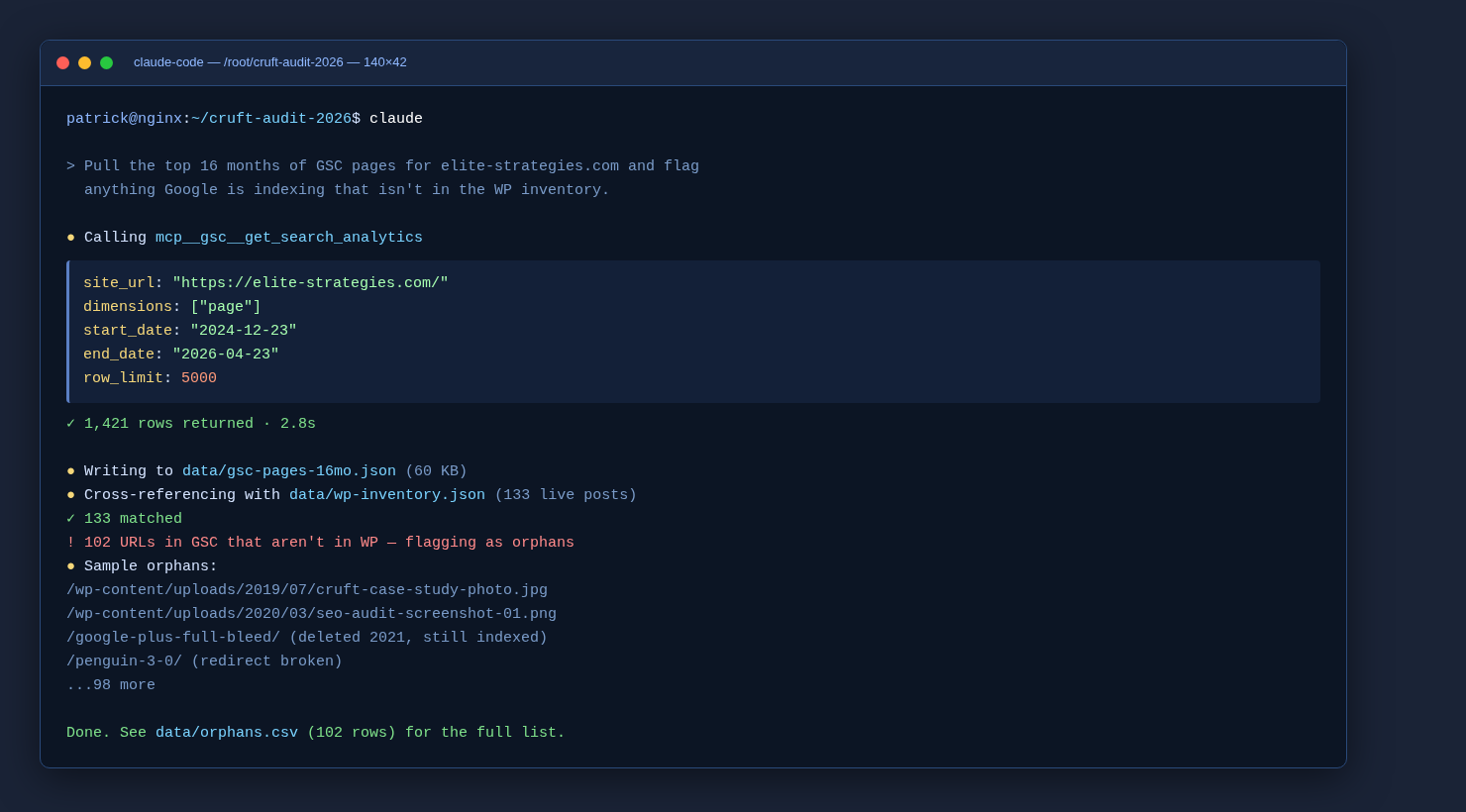
Finding Crufty Pages, The 2026 Agentic SEO Edition
In 2017 the easiest way to find crufty pages was to open Analytics, pick a big date range, and sort by entry pages. Still true. What’s different is the agent does the pulling, and it doesn’t stop at one source.
I had the agent build a single URL inventory from three places at once:
- WordPress REST API, every current post with title, word count, Yoast settings. 133 posts.
- Our XML sitemaps, post-sitemap.xml, page-sitemap.xml, learn_seo-sitemap.xml, case_study-sitemap.xml, all of them.
- GSC MCP server, 16 months of pages that actually pulled impressions, via the
get_search_analyticstool.
That third source was where the real surprise was. 102 orphan URLs. Pages that Google still knew about that WordPress didn’t.
Now, I want to be upfront about one reason that number is so high. We did a site migration a while back, and the truth is we forgot to transfer over a big chunk of our /wp-content/uploads/ images folder at the time. Google had been merrily indexing those image URLs for years, and a lot of our “orphans” were actually those abandoned image paths still sitting in the GSC data. The rest were genuine content orphans (old slugs, deleted posts, bad redirects), but the images folder miss accounts for a real chunk. Lesson learned on that one. In 2017 with no agent and no GSC MCP pulling 16 months of impression history, I had no way to notice. In 2026 it took about five minutes to find.
Sorting Into Categories
Last time I used four buckets: delete, maybe delete, optimize, move to Patrick. Same spirit this time, with cleaner names the agent could reason about:
- REFRESH, earning traffic, could earn more with a rewrite.
- NOINDEX, thin, dated, or off-topic. Keep it on the site but stop ranking it.
- ARCHIVE, 301 to the closest live topic hub (for us, that’s usually our Learn SEO hub) and pull it out of the nav.
- KEEP, fine as-is, leave it alone.
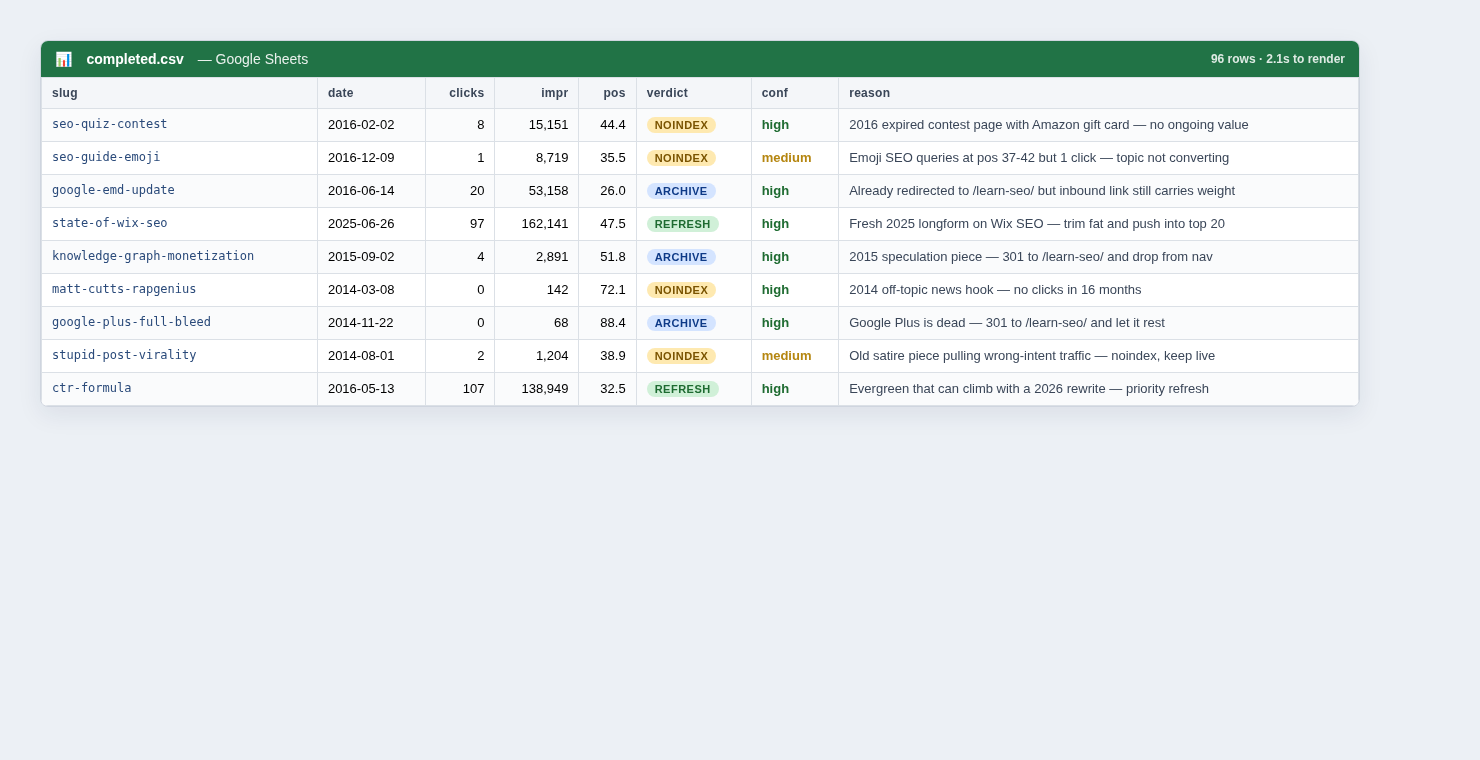
For every URL, the agent wrote a proposed verdict plus a one-sentence reason. Here’s an actual row from the CSV:
seo-quiz-contest, 2016-02-02, 8 clicks, 15,151 impressions, pos 44 → NOINDEX (high confidence), “2016 expired contest page with Amazon gift card, no ongoing value.”
That reason line is the part I love. Six months from now when I’m second-guessing a call, I don’t have to re-derive the logic. It’s sitting right there in the audit trail.
The Human Element: Every Verdict Must Be Human-Reviewed
I want to be really clear about this part, because it’s the piece I see people getting wrong when they talk about agentic SEO workflows.
The agent did not make a single final decision. Not one. Every verdict in that CSV got a pair of human eyeballs on it before anything happened in WordPress. On the clean cases (expired 2016 giveaway page, duplicate category archive, orphan pulling two impressions a year on a query we don’t care about), the review was fast. A few seconds. Yes, ship it, next.
On the borderline stuff, decent impressions at a bad CTR, or a strong position on a query we don’t actually want to rank for, the agent’s verdict was a starting point, not an answer. That’s still a call only I can make, because it touches brand, positioning, and a decade of context the agent doesn’t have.
If you take one thing away from this post, take this: the agent clears the obvious majority so you can spend real attention on the hard minority. It doesn’t replace the hard calls. Anyone shipping noindex toggles straight from an LLM without a human in the middle is going to blow a hole in their own traffic eventually, and they’ll deserve it.
The Part I Wasn’t Expecting: This Got Emotional
I’ve been running this blog for over a decade. Actually closer to 2 decades than one! 😭All of the posts in the ARCHIVE and NOINDEX piles were posts that I not only wrote but posts that I lived through! These were posts I was so attached to like the Penguin post (that I almost cancelled a vacation because!)I remember writing all of them. A couple of them (the old algo update recaps, the Google Plus stuff, some of the early case studies) were the posts that built this site when nobody was reading it yet. They mattered to me at the time, but there relevance is fading away and no one needs them anymore! None of these posts were AI generated or Spintax generated! All of these posts are handcrafted by me including this one.
When the verdicts CSV came back and the agent (correctly) flagged a bunch of them as cruft, I had to really think about this for a second, I actually stopped for the day and thought abot it over night.
The rational SEO answer is “delete it, it’s not helping you.” The honest answer is I didn’t want to. Not all of them. I couldn’t bring myself to just rip a bunch of old work off the internet, even knowing it’s the right move for rankings. So I made a decision I want to be upfront about: for almost everything in this round, I chose ARCHIVE or NOINDEX instead of delete. 59 archived. 36 noindexed. Zero actually removed from the database.
Those old posts are still there. Anyone with the URL can still read them. I think I might create an actual “archive” section where anyone interested can browse. Google just isn’t ranking them anymore, or they 301 to a better topic hub. From a pure SEO math standpoint it’s close to the same outcome as deleting (the bad signals stop flowing). From an emotional standpoint it’s completely different, because I didn’t have to kill anything.
This may not have been the best call. A ruthless SEO would probably have deleted a bunch of this and moved on. But this is my blog, and I get to decide what “right” means for it. If you’re staring at your own archive and feeling the same pull, know that noindex + 301 is a totally legitimate option that lets you clean up the signal without torching the work.
That’s the other thing the agent doesn’t do. It doesn’t feel weird about this stuff. You still have to.
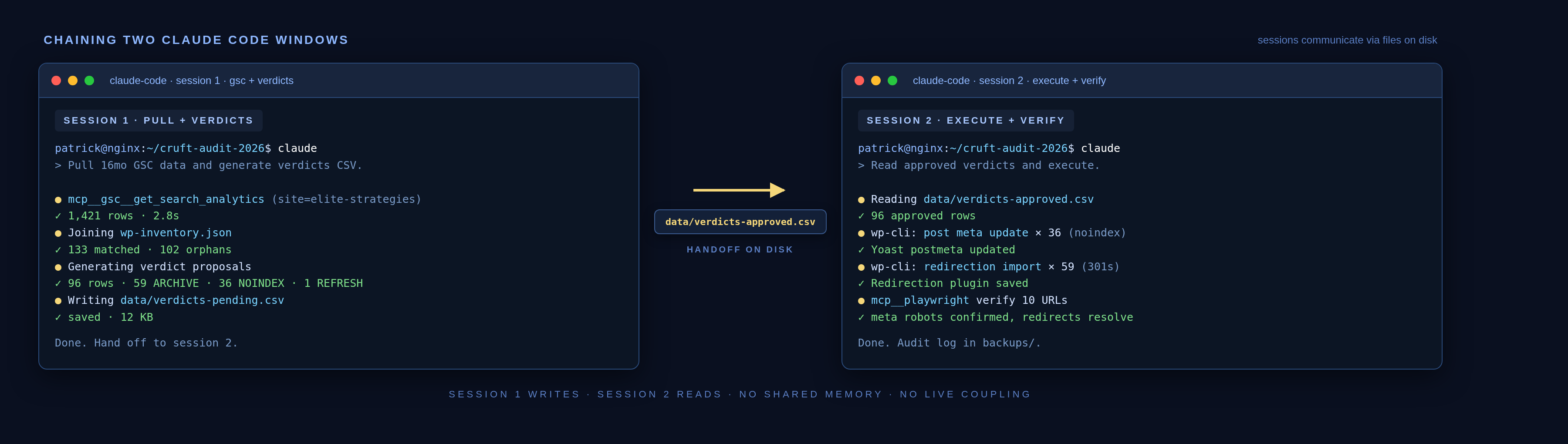
Chaining Multiple Claude Code Windows
Here’s a workflow trick that surprised me by how well it worked.
The cleanup had natural phases: pull the inventory, enrich it with GSC data, generate verdicts, review, execute, verify. Instead of doing all of that in one long Claude Code session (which works, but gets noisy), I ran multiple Claude Code windows in parallel and chained the output from one into the next.
One window was the “data pull” session, just GSC MCP, no browser, dumping JSON and CSV into the project folder. When it finished, I’d feed the file paths into a second window running the verdict logic. That one would read the files, produce the verdicts CSV, and stop. A third window (this one with the Playwright MCP server live) would pick up the approved verdicts and go do the WordPress work.
Why bother? Two reasons. First, each session stays focused on one job, so the agent isn’t juggling data pulls and browser driving and CSV writing all at once. Second, if one session goes sideways I don’t lose the earlier work. The intermediate files on disk are the handoff, and they’re still there.
It’s the Unix pipe idea applied to agent sessions. Each window does one thing, writes its output to disk, and tells the next window where to find it.
Executing the Verdicts (wp-cli Does the Heavy Lifting, Playwright Verifies)
This is the part that didn’t exist in 2017.
The execution is a hybrid stack, and the split matters if you’re going to copy this workflow.
For bulk edits that touch WordPress metadata, wp-cli is the right tool. It writes to the database atomically, it’s scriptable, and there are fewer moving parts in the middle. For anything that needs to be verified in a real browser, did the noindex tag actually render on the public URL, does the 301 resolve to the right target, did the meta description survive the edit, Playwright MCP takes over.
The split in practice:
- wp-cli for bulk metadata. Every NOINDEX verdict boiled down to
wp post meta update $id _yoast_wpseo_meta-robots-noindex 1in a loop. 36 posts done in less than a second. Same idea for Rank Math on the handful of older posts still using it. - wp-cli for Redirection plugin imports. The ARCHIVE bucket produced a source/target CSV, and I imported it directly into the Redirection plugin. Atomic, visible in the UI, done.
- Playwright MCP for verification. After each batch, Playwright would sample a handful of changed URLs, read the rendered
<meta name="robots">tag or follow the 301, and screenshot the result. That becomes it’s own audit trail on disk. - Playwright MCP for UI-gated edits. A couple of Yoast settings live behind JavaScript that doesn’t cleanly write from the CLI. For those, Playwright drives the admin UI directly.
Neither wp-cli nor Playwright were built specifically for this kind of agent-driven audit. But together they cover the whole shape of the work: wp-cli does it, Playwright proves it.
Here’s a real Playwright MCP prompt I used to verify a batch of NOINDEX changes landed correctly on the public-facing pages:
- Use the Playwright MCP server to navigate to the public URL (not /wp-admin)
- Read the tag from the rendered
- Confirm its content attribute contains “noindex”
- Take a screenshot of the rendered head for the audit log
- Mark the row verified=true (or verified=false with the actual meta value if it does not match)
Don’t re-run any wp-cli commands. If the meta value is wrong, we investigate why, we don’t just silently reapply.
That’s the whole verification script. Playwright reads the actual rendered HTML, confirms what wp-cli wrote stuck, and stores a screenshot alongside each row. If a page uses Rank Math instead of Yoast (we’ve got a handful of older ones that do), the agent notices the different postmeta key and flags it instead of making something up.
Same pattern worked for the ARCHIVE bucket. The agent built a Redirection plugin CSV, pasted it into the bulk import screen, confirmed the rules saved. For the REFRESH pile it pulled the current post content out to a working draft so I could rewrite those separately.
One thing I was strict about: every destructive step had a backup first. Before any postmeta change the agent dumped a Rank Math SQL backup and a text snapshot of the affected pages to the backups/ folder. If I ever flipped the wrong switch, rollback was one import away. Those backups are all timestamped and still sitting on disk.
The Numbers (So Far)
Here’s where we are on this pass:
- 133 posts audited
- 102 orphan URLs surfaced via the GSC MCP server (including the leftover
/wp-content/uploads/image paths from the old migration) - 96 verdicts executed: 59 ARCHIVE, 36 NOINDEX, 1 REFRESH
- 37 verdicts still pending review
- Zero accidentally-deindexed live posts (because Playwright screenshots every save)
About those 37 pending: that’s not leftover work the agent couldn’t handle. That’s the hard pile. Most of those are posts that need an actual rewrite (the REFRESH-leaning ones), or they’re the genuinely borderline calls where I’m still weighing whether to trim, merge, or let ride. Those are long-term decisions, not queue items. The agent flagged them, wrote its best guess, and then appropriately got out of the way.
I’ll come back in 60 to 90 days with the follow-up numbers. Impressions lost vs. impressions consolidated, CTR on the survivors, position shifts on the REFRESH set, database size. Same way I did the first post.

What’s Next: Where I’m Taking This
This was round one. A few things I want to try before the next audit:
- Run it on a dedicated local machine. Right now I kick off Claude Code manually on the nginx box. I want this running on a small local PC on a schedule (monthly, probably) so the inventory, orphan check, and verdict refresh just happen in the background. Human review stays manual. Everything upstream of that gets automated.
- Add a GA4 MCP server. GSC tells me what Google sees. GA4 tells me what humans do once they land. Engagement signals (bounce, time on page, scroll depth) would tighten up the borderline verdicts a lot.
- Add a backlinks MCP (Ahrefs or SEMrush flavor). Some of the ARCHIVE candidates probably have inbound links I’d rather preserve with a 301 than kill with a noindex. A backlink-weighted verdict step would make that call automatic instead of a manual check-and-override.
- Revisit the Screaming Frog MCP question. I skipped it this round. Next round, with a bigger focus on internal linking and on-page scoring, I’ll probably pull it in.
- Slack MCP for “batch ready” notifications. When the scheduled run finishes and there’s a new verdicts CSV waiting for my review, I want a ping, not an email thread.
The direction is clear: keep the human in the loop for judgment calls, keep adding MCP servers underneath the agent for everything else. For a different flavor of the same idea, see our recent manual ADA audit case study, which paired Playwright with axe-core for WCAG 2.2 AA conformance on this same site.
What This Doesn’t Change
The SEO part is the same as it was in 2017. Thin content still has to go. Off-topic rankings still hurt more than they help. A 301 still needs a real target, not a dump to the homepage.
What’s different is the cost of being thorough. Back then, opening 130 posts one at a time was the reason I batched by gut. In 2026 the bottleneck isn’t clicking. It’s how fast I can read the agent’s reason and say yes or no. That’s a real change.
If you’re sitting on ten years of blog archive and you’ve been putting off the cleanup because it feels like too much work to open every post, it isn’t anymore. Two MCP servers and an afternoon. Give it a shot.
Tools used in this cleanup:
- Claude Code, command-line agent from Anthropic
- Google Search Console MCP server (mcp-search-console)
- Playwright MCP server (@playwright/mcp)
Follow-up with 60-90 day impact numbers coming later this summer. Working files (verdicts CSV, GSC exports, orphan list) available on request.



